
What's Lasciva Roma ?
Lasciva Roma is a long-term project looking at the history of sexuality in Rome and in Latin using a computational approach, in particular text mining, automatic subject detection and sentence classification.
This page brings together all the tools and data (reused or produced) that are openly accessible under a free licence, allowing the products of the project not only to be used for a similar purpose (history of sexuality) but also to be reused for other scientific purposes.
Quick access
- Who's behind it?
- Publications
- Datasets
- Database of Latin Sexual Discourses
- Latin Lemmatized Texts
- Lexical Resources
- Priapea
- Gold corpus of Latin lemmatised and annotated in morpho-syntax
- DigilibLT Corpus
- Additional Texts
- Tools and websites
Who's behind it ?
My name is Thibault Clérice, and my whole PhD was around this specific topic. I am a trained classicist and digital humanist. I have worked for projects such as Perseus and Perseids before becoming a doctor. My PhD thesis was defended in March 2023 with the title "Detecting Isotopies using Deep Learning : the Example of Sexuality in Classical and Late Latin" under the supervision of C. Nicolas (Lyon, France).
You can find me online at various locations:

"Classic" publications
PhD Thesis
Abstract: In 1982, James N. Adams produced the reference study of the Latin sexual vocabu-lary. In his book, the author presented a wide range of words or expressions refined by their stylistic (metaphor, metonymy, etc.) and semantic (war, cooking, hunting, vio-lence...) features for various categories (acts, male and female pudenda, etc.). Around the same time, François Rastier refined the definition of isotopy as the “the recurrence of the same semantic feature” in a text. We built a completely new Latin meta-corpus of 20 million words in TEI based on the works of existing projects and news sources. Using this meta-corpus and the work of Adams, we built a new completely new digital “handout” that provide 2500 examples of Latin sexual isotopies. To treat the corpus, we developed a method and the tools to lemmatize and annotate morphological and syntactical features of Classical and Late Latin texts. Finally, we set ourselves up to test deep learning methods to detect isotopies in Latin texts spanning from -200 BCE up to the 700 CE. This method should provide the foundation for building new “vocabularies” for other isotopies in the future. A selection of methods show robust results with a full corpus, and we discuss the limits of these models based on the corpus size or the difficulty of the task.
Links: Download PDF -- Download LaTeX -- Experiment code -- Semantic Classifier
"Don't worry, it's just noise": quantifying the impact of files treated as single textual units when they are really collections
Abstract: Literature works may present many autonomous or semi-autonomous units, such as poems for the first or chapter for the second. We make the hypothesis that such cuts in the text's flow, if not taken care of in the way we process text, have an impact on the application of the distributional hypothesis. We test this hypothesis with a large 20M tokens corpus of Latin works, by using text files as a single unit or multiple "autonomous" units for the analysis of selected words. For groups of rare words and words specific to heavily segmented works, the results show that their semantic space is mostly different between both versions of the corpus. For the 1000 most frequent words of the corpus, variations are important as soon as the window for defining neighborhood is larger or equal to 10 words.
Links: Download PDF -- Download LaTeX
Datasets
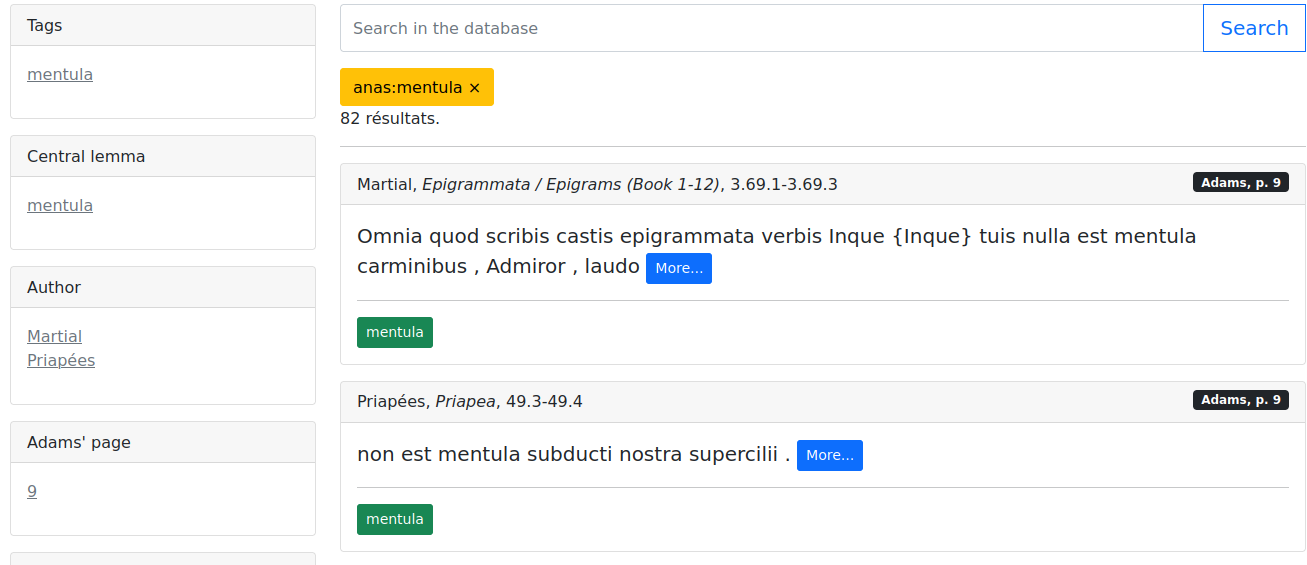
Database of Latin Sexual Discourses
The Database of Latin Sexual Discourses contains 2500 excerpts of Latin Literature where sexual content is discussed (e.g. reproduction, medical approach) or used (e.g. aggressive use of sexuality). All excerpts were annotated manually (see below for source) and contain a single analysis of a specific sense of a word or group of words. Each excerpt is identified through the original CTS URN of the excerpt as well as the version and source of the text. All excerpt are automatically annotated regarding linguistic features (lemma, POS, morphology).
It is originally based on the work of James Noel Adams, The Latin Sexual Vocabulary (it can actually be used as a companion app when reading the latest).
The Latin Lemmatized Texts
The Latin Lemmatized Texts is a set of 21.3 million lemmatized tokens with POS and morphological analysis. Each token is identified within the citation scheme of the text, according to the Canonical Text Services URN system, and in general to the citation schemes of classical texts. The lemmatization is versioned. Six source corpora are used to build this corpus: the source of each text is provided, along with the version of the lemmatizer and model at the time of the last update.
Reused by: Grotto et al., The Annotation of Liber Abbaci, a Domain-Specific Latin Resource [Link].
Reused by: Alpheios [Link].

Lexical Resources
The Ground truth and Models for Lexical Resources OCR is a set of 3 Latin lexicons: 1 Latin-French & 1 Latin-only lexicons on sexuality; 1 Latin-Latin synonym lexicon. It contains the original data (from Archive.org, Gutenberg, etc.), the scripts to generate the final items as well as the final items in XML TEI.
Links: Github

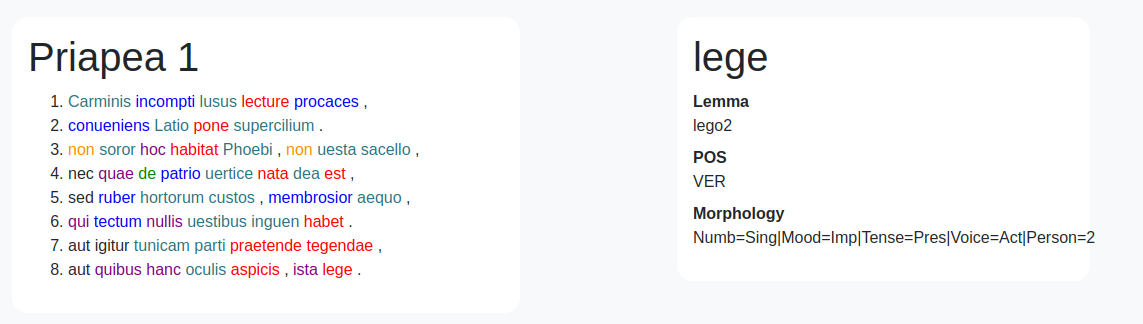
Priapea and Lemmatized Priapea
The Priapea is a very important book for the history of sexuality in Latin, as it contains roughly 80 poems about sex or Priapus in general (specifically, when it's not about sex, it's about protecting gardens). The Priapea have been edited in TEI, reusing an original transcript of an unknown edition, and aligning with the Teubner edition of 1879 (Public Domain). All Priapea have been annotated manually in a secondary repository with lemma, POS and morphology.
Links: Github of the Edition -- Github for annotations -- Lemmatization vizualisation
Reused by: Perseus Scaife Viewer, [Link].
[Collab] From the 2nd century to Thomas More, a gold corpus of Latin lemmatised and annotated in morpho-syntax
This corpus has been designed by Anthony Glaise and Thibault Clérice for testing the robustness of our MSD and lemmatization models trained on classical Latin data. It was built in three phases, which you can find in raw.
Anthony Glaise corrected and checked all annotations, chose most of the texts with guidelines by Thibault Clérice. Thibault Clérice provided data engineering, technical support, annotations guidelines and data analysis (publication forthcoming)..

[Reuse] DigilibLT Corpus
[Quote from the original website]: "The Digital Library of Late-Antique Latin Texts—DigilibLT—publishes secular prose texts written in Latin in late antiquity (from the second to the seventh century AD). The texts are annotated according to the XML-TEI standards and are offered free of charge to the public for reading and research."
This version of the DigilibLT corpus makes use of the Capitains definition of passages and structures, in order to make passages machine-actionable
Links: Original Website -- Github Reuse

[Reuse] Additional Texts
This corpus provides Capitains XML TEI versions of document either not available in standard XML TEI format or in machine actionable Capitains encoding. It provides unique texts, including an edition adapted from the PDF of the PhD thesis of Dr. Lesley Bolton (Calgary) who gave us the authorization to publish it openly.
Links: Github
Tools and models
Pie-Extended
Pie-Extended is a lemmatizer and POS-tagger which includes pre- and post-processing of the content to adapt the data to be tagged according to ground truth standards. It is a wrapper for PaPie.
Links: Github -- Latin Model
Reused by: B. Nagy, Rhyme in classical Latin poetry: Stylistic or stochastic? (2022) [Link]